The execution of Information Science to any issue requires a bunch of abilities. AI is a necessary piece of this range of abilities.
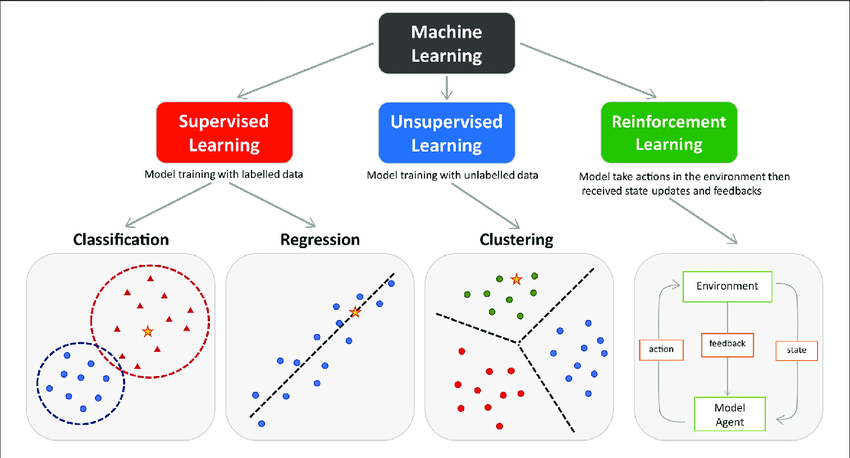
For doing Information Science, you should realize the different AI calculations utilized for taking care of various sorts of issues, as a solitary calculation can't be awesome for a wide range of purpose cases. These calculations find an application in different assignments like expectation, order, bunching, and so on from the dataset viable.
In this article, we will see a short prologue to the top Information Science calculations.
Read Also: Do Machine Learning Engineers Need To Know Data Structures And Algorithms?
Top 7 Data Science Algorithms
The most well known AI calculations utilized by the Information Researchers are:
1. Linear Regression
Straight relapse technique is utilized for anticipating the worth of the reliant variable by utilizing the upsides of the autonomous variable.
The straight relapse model is reasonable for anticipating the worth of a constant amount.
y is the reliant variable whose esteem we need to anticipate.
x is the free factor whose values are utilized for anticipating the reliant variable.
b0 and b1 are constants in which b0 is the Y-catch and b1 is the slant.
2. Logistic Regression
Straight Relapse is constantly utilized for addressing the connection between a few ceaseless qualities. Notwithstanding, in spite of this Calculated Relapse deals with discrete qualities.
Calculated relapse finds the most well-known application in taking care of parallel grouping issues, that is to say, when there are just two prospects of an occasion, either the occasion will happen or it won't happen (0 or 1).
Consequently, in Strategic Relapse, we convert the anticipated qualities into such qualities that lie in the scope of 0 to 1 by utilizing a non-straight change capability which is known as a calculated capability.
The calculated capability brings about a S-molded bend and is consequently likewise called a Sigmoid capability given by the situation,
3. Decision Trees
Choice trees help in taking care of both order and expectation issues. It makes it straightforward the information for better precision of the expectations. Every hub of the Choice tree addresses an element or a trait, each connection addresses a choice and each leaf hub holds a class mark, or at least, the result.
The disadvantage of choice trees is that it experiences the issue of overfitting.
Fundamentally, these two Information Science calculations are generally normally utilized for carrying out the Choice trees.
ID3 ( Iterative Dichotomiser 3) Calculation
This calculation utilizes entropy and data gain as the choice measurement.
Truck ( Order and Relapse Tree) Calculation
This calculation utilizes the Gini list as the choice measurement. The beneath picture will assist you with understanding things better.
4. Naive Bayes
The Gullible Bayes calculation helps in building prescient models. We utilize this Information Science calculation when we need to work out the likelihood of the event of an occasion from here on out.
Here, we have earlier information that another occasion has previously happened.
The Innocent Bayes calculation chips away at the presumption that each component is autonomous and has a singular commitment to the last forecast.
The Gullible Bayes hypothesis is addressed by:
P(A|B) = P(B|A) P(A)/P(B)
Where An and B are two occasions.
P(A|B) is the back likelihood for example the likelihood of A given that B has proactively happened.
P(B|A) is the probability for example the likelihood of B given that A has previously happened.
P(A) is the class before likelihood.
P(B) is the indicator earlier likelihood.
5. KNN
KNN represents K-Closest Neighbors. This Information Science calculation utilizes both arrangement and relapse issues.
The KNN calculation considers the total dataset as the preparation dataset. Subsequent to preparing the model utilizing the KNN calculation, we attempt to foresee the result of another significant piece of information.
Here, the KNN calculation look through the whole informational collection for recognizing the k generally comparable or closest neighbors of that data of interest. It then predicts the result in light of these k occasions.
For finding the closest neighbors of an information occurrence, we can utilize different distance estimates like Euclidean distance, Hamming distance, and so on.
To all the more likely get it, let us think about the accompanying model.
6. Support Vector Machine (SVM)
Support Vector Machine or SVM goes under the class of directed AI calculations and tracks down an application in both arrangement and relapse issues. It is generally normally utilized for characterization of issues and orders the data of interest by utilizing a hyperplane.
The initial step of this Information Science calculation includes plotting every one of the information things as individual focuses in a n-layered diagram.
Here, n is the quantity of elements and the worth of every individual component is the worth of a particular direction. Then we find the hyperplane that best isolates the two classes for ordering them.
Finding the right hyperplane assumes the main part in characterization. The information focuses which are nearest to the isolating hyperplane are the help vectors.
7. K-Means Clustering
K-implies grouping is a sort of unaided AI calculation.
Bunching essentially implies partitioning the informational collection into gatherings of comparable information things called groups. K means bunching orders the information things into k gatherings with comparable information things.
For estimating this comparability, we utilize Euclidean distance which is given by,
D = √(x1-x2)^2 + (y1-y2)^2
K means grouping is iterative in nature.
The essential advances followed by the calculation are as per the following:
To begin with, we select the worth of k which is equivalent to the quantity of bunches into which we need to sort our information.
Then we allocate the arbitrary focus values to every one of these k bunches.
Presently we begin looking for the closest information focuses to the bunch habitats by utilizing the Euclidean distance recipe.
In the following stage, we ascertain the mean of the information focuses allocated to each bunch.
Again we look for the closest information focuses to the recently made focuses and relegate them to their nearest groups.
We ought to continue to rehash the above strides until there is no adjustment of the information focuses allocated to the k groups.
 Wolski Kala
Wolski Kala
The execution of Information Science to any issue requires a bunch of abilities. AI is a necessary piece of this range of abilities.
For doing Information Science, you should realize the different AI calculations utilized for taking care of various sorts of issues, as a solitary calculation can't be awesome for a wide range of purpose cases. These calculations find an application in different assignments like expectation, order, bunching, and so on from the dataset viable.
In this article, we will see a short prologue to the top Information Science calculations.
Read Also: Do Machine Learning Engineers Need To Know Data Structures And Algorithms?
Top 7 Data Science Algorithms
The most well known AI calculations utilized by the Information Researchers are:
1. Linear Regression
Straight relapse technique is utilized for anticipating the worth of the reliant variable by utilizing the upsides of the autonomous variable.
The straight relapse model is reasonable for anticipating the worth of a constant amount.
y is the reliant variable whose esteem we need to anticipate.
x is the free factor whose values are utilized for anticipating the reliant variable.
b0 and b1 are constants in which b0 is the Y-catch and b1 is the slant.
2. Logistic Regression
Straight Relapse is constantly utilized for addressing the connection between a few ceaseless qualities. Notwithstanding, in spite of this Calculated Relapse deals with discrete qualities.
Calculated relapse finds the most well-known application in taking care of parallel grouping issues, that is to say, when there are just two prospects of an occasion, either the occasion will happen or it won't happen (0 or 1).
Consequently, in Strategic Relapse, we convert the anticipated qualities into such qualities that lie in the scope of 0 to 1 by utilizing a non-straight change capability which is known as a calculated capability.
The calculated capability brings about a S-molded bend and is consequently likewise called a Sigmoid capability given by the situation,
3. Decision Trees
Choice trees help in taking care of both order and expectation issues. It makes it straightforward the information for better precision of the expectations. Every hub of the Choice tree addresses an element or a trait, each connection addresses a choice and each leaf hub holds a class mark, or at least, the result.
The disadvantage of choice trees is that it experiences the issue of overfitting.
Fundamentally, these two Information Science calculations are generally normally utilized for carrying out the Choice trees.
ID3 ( Iterative Dichotomiser 3) Calculation
This calculation utilizes entropy and data gain as the choice measurement.
Truck ( Order and Relapse Tree) Calculation
This calculation utilizes the Gini list as the choice measurement. The beneath picture will assist you with understanding things better.
4. Naive Bayes
The Gullible Bayes calculation helps in building prescient models. We utilize this Information Science calculation when we need to work out the likelihood of the event of an occasion from here on out.
Here, we have earlier information that another occasion has previously happened.
The Innocent Bayes calculation chips away at the presumption that each component is autonomous and has a singular commitment to the last forecast.
The Gullible Bayes hypothesis is addressed by:
P(A|B) = P(B|A) P(A)/P(B)
Where An and B are two occasions.
P(A|B) is the back likelihood for example the likelihood of A given that B has proactively happened.
P(B|A) is the probability for example the likelihood of B given that A has previously happened.
P(A) is the class before likelihood.
P(B) is the indicator earlier likelihood.
5. KNN
KNN represents K-Closest Neighbors. This Information Science calculation utilizes both arrangement and relapse issues.
The KNN calculation considers the total dataset as the preparation dataset. Subsequent to preparing the model utilizing the KNN calculation, we attempt to foresee the result of another significant piece of information.
Here, the KNN calculation look through the whole informational collection for recognizing the k generally comparable or closest neighbors of that data of interest. It then predicts the result in light of these k occasions.
For finding the closest neighbors of an information occurrence, we can utilize different distance estimates like Euclidean distance, Hamming distance, and so on.
To all the more likely get it, let us think about the accompanying model.
6. Support Vector Machine (SVM)
Support Vector Machine or SVM goes under the class of directed AI calculations and tracks down an application in both arrangement and relapse issues. It is generally normally utilized for characterization of issues and orders the data of interest by utilizing a hyperplane.
The initial step of this Information Science calculation includes plotting every one of the information things as individual focuses in a n-layered diagram.
Here, n is the quantity of elements and the worth of every individual component is the worth of a particular direction. Then we find the hyperplane that best isolates the two classes for ordering them.
Finding the right hyperplane assumes the main part in characterization. The information focuses which are nearest to the isolating hyperplane are the help vectors.
7. K-Means Clustering
K-implies grouping is a sort of unaided AI calculation.
Bunching essentially implies partitioning the informational collection into gatherings of comparable information things called groups. K means bunching orders the information things into k gatherings with comparable information things.
For estimating this comparability, we utilize Euclidean distance which is given by,
D = √(x1-x2)^2 + (y1-y2)^2
K means grouping is iterative in nature.
The essential advances followed by the calculation are as per the following:
To begin with, we select the worth of k which is equivalent to the quantity of bunches into which we need to sort our information.
Then we allocate the arbitrary focus values to every one of these k bunches.
Presently we begin looking for the closest information focuses to the bunch habitats by utilizing the Euclidean distance recipe.
In the following stage, we ascertain the mean of the information focuses allocated to each bunch.
Again we look for the closest information focuses to the recently made focuses and relegate them to their nearest groups.
We ought to continue to rehash the above strides until there is no adjustment of the information focuses allocated to the k groups.